

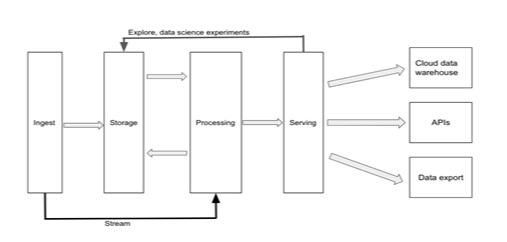
Layers of Data Platform
- Ingestion Layer
- Storage Layer
- Processing Layer
- Serving Layer
Ingestion Layer
It’s all about getting data into data platform. Data sources coming from or reaching to Relational or NoSQL databases, files storage, Internal or 3rd party API’s to extract data.
This layer should not modify or transform the incoming data in any way. This is RAW, unprocessed data is always available in data lake for data lineage tracking and re-processing.
Storage Layer
After acquired different data sources, it should be stored on this layer. Here it is coming data lake storage, which is scalable and inexpensive. It’s been without any restrictions on any types of files ( Text, csv, JSON, binary files like parquet, images, video and Avro).
Processing Layer
After data stored into cloud Data Lake, It’s ready to process to meaningful. Traditional Data warehouse has many tools to process like SQL and ETL tools.
Data processing framework can handle any amount of data with cloud compute resource. Few are most notable are:
- Apache Spark
- Glue
- Python
Important thing to keep in mind that,
For Batch processing – Which is mentioned in diagram for ingestion layer to stored layer and then Processing layer is works well.
For Streaming Process – Instead of stored layer directly process the streaming data from Ingestion layer to Process layer. Here, cloud stored layer used as Archive process.
Processing data in data platform includes many distinct steps of Schema management, data validation, data cleansing, Production of data products.
Serving Layer
This layer used for preparing data for end-users or systems. Power users and analysts run ad-hoc sql queries, Data Scientists and Developers use the programming language where they most comfortable with to prototype new data transformation or build machine learning models.
Cloud makes it easy to access different task by using single architecture like load data from data lake into cloud data warehouse.
- Provide Data Lake access to other applications, load data from Lake into a fast KEY/VALUE or Document Store and point the application to that.
- For Data Science and engineering teams, Cloud Data lake provides an environment where they can work with the data directly in cloud storage by using a processing framework like Spark or Flink.
Cloud Data Platform – Handling 3 V’s (Variety, Volume and Velocity)
Variety
Cloud platform accepts any form of data or data types which is no limitations or restrictions.
There are plug-and-play ingestion tools for storing into cloud platform like Kafka Connect, Apache NiFi.
Volume
Cloud storage is elastic which is pay for use method which makes inexpensive for data volume.
Velocity
When data scientists are users for the data systems, volume and variety challenges come into play all at once.
Two more V’s
Veracity
Maintain data governance for accuracy in big data platforms .
Value
Turning data into value only by data users or systems, when get timely and effectively access to data.
Leave feedback about this