

Cloud Data Architecture – 4-Layer Vs 6-Layer
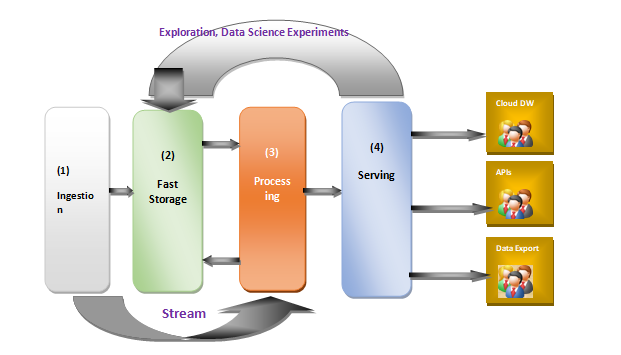
4 Layer Data Architecture
 .
.
- Ingestion Layer
Connects source system and brings source data into data lake and preserve original format. It should follow pluggable architecture, scalability, High availability and Observability.
- Storage Layer
Store, maintain and archive data in this layer. It may have slow storage or fast storage.
- Processing Layer
Heart of data platform architecture where apply all business validation and transformations happening here.
- Serving layer
Consume by system or people of curated form of data.
6 Layer Data Architecture
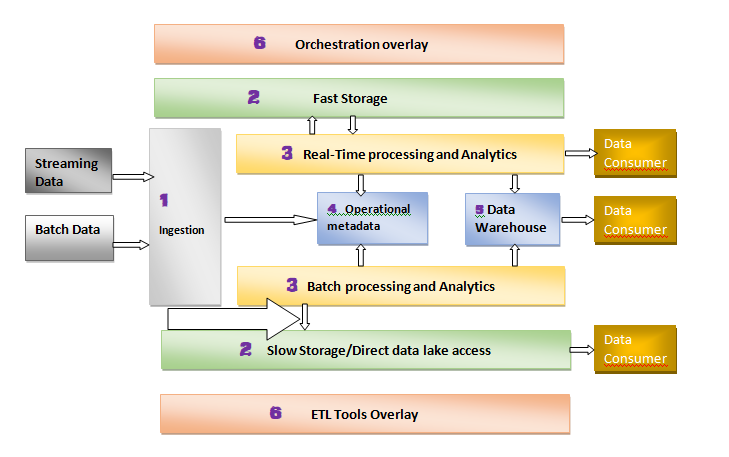
Streaming Data
One event- at-a-time data access for streaming data
Batch Data
Systems with Batch-only access patterns for CSV, JSON and XML files on FTP servers
- Ingestion Layer
Connects source systems and brings data into Data lake and preserving the original data format.
Below are the properties to delivering data efficiently into Data-Lake in Ingestion Layer.
- Pluggable Architecture – New Data source connector should be created significantly less effort.
- Scalability –Data ingestion layer should not be revamp completely when ingest the data in future
- High Availability – Data ingestion layer should handle failures of individual components like disk, n/w, or full virtual machine failures and still able to deliver data to data platform.
- Observability – Data ingestion layer should manage and expose critical metrics like latency, throughput, memory, CPU, disk utilization and external monitoring tools.
- Fast and Slow Storage Layer
Slow Storage – This is main storage for archive & persistent data which has no compute process
Fast Storage – Low latency read/write operations on a single message(Kafka Streams). Compute capacity is associated with storage itself which based on how fast to process data(CPU and RAM)
Process Real time data -> Cloud DataFlow and Kafka Streams
Properties
Reliable – Both slow and fast storage should be persist data in case of failures.
Scalable – Add extra storage capacity with minimal efforts
Performant
- Read large volume of data with high throughput from slow storage
- Read/write messages with low latency to fast storage
Cost Efficient- Data retention policy to optimize storage to optimize cost
- Processing Layer
A distributed data processing engine is a must. You might need separate ones for batch and for real time.
- Heart of data platform implementation
- Apply all business logic, business validation and transformations happening here
- Store back it to storage layer after processing the data for analysts and data scientists.
- Deliver data outputs to consumers or other systems
Properties
- Scale beyond a single machine
- Data processing framework or cloud service should be handle Terra Bytes or Peta Bytes
- Should support both stream and batch process
- Should support programming language of Python, Scala and Java
- Added advantage if supports SQL Interface.
- Technical Meta Data layer
- Store/maintain Schema info of DB sources
- Status of ingestion, transformation pipelines like success, failure, errors, warnings, row count, data lineage of processed data.
Properties
Scalable – Hundreds of individual tasks are running parallel in data platform environment. The meta data must be scale to provide fast responses of all tasks.
Highly Available – Single point of failure in data platform pipelines. All tasks are performing on fetch, add, delete and update process based on meta data stored on this layer. If this failed the rest of the process might fail.
Extendable – No restrictions on what meta data info is stored. It should be extendable.
- Serving Layer and Data Consumers
- Consumers are both people and system, some consumes RAW data and others consume organized curated data via Data warehouse.
- So, both Data consumers Data warehouse are part of Serving Layer
- Serving Layer almost always include a Data warehouse
Properties
Scalable and Reliable: Cloud DW supports both small data sets and large data sets beyond single computer capacity. It must serve data in the face of inevitable failures or individual components.
NoOps: Required little tuning or operational maintenance
Elastic Cost Model : Cost model should be effective when off-hour process.
Slow storage/direct data lake access
Direct data lake access allows consumers to bypass serving layer and work directly with raw and un-processed data.
Data science, data exploration and experimentation falls into this category. So, this layer will not impact the performance when business user accessing dashboard from Data warehouse.
Reading raw data from storage by data scientists for ML applications.
Real-time processing and analytics
Outputs from a real-time analytics pipeline are usually consumed by other applications not users.
- Orchestration and ETL overlay layers
Orchestration Layer
- Define sequence and dependency of jobs – Scheduler
- Apache Airflow is most popular open source tool.
ETL Tools Overlay
A product or a suite of products to make the implementation and maintenance of data pipelines easier. ETL overlay tools can implement almost all layers of cloud data platform architecture.
- Adding data ingestion from multiple sources ( Ingestion Layer )
- Create data processing lines ( Processing Layer )
- Store some of the meta data about pipelines (Metadata Layer)
- Orchestration of jobs ( Orchestration Layer)
Can implement a data platform by using single tool and not worrying about implementing and managing separately?
Consider below questions when fully rely only an ETL overlay tools.
- How flexible it is to extend it?
- Is that possible to add new components for data ingestion layer?
- Can you do data processing only ETL service facilities or can call external data processing components?
- Can Integrate other 3rd party services?
- Can use open source ETL tools?
There is NO SYSTEM IS STATIC. If ETL service is not providing for extending its functionality or integrating with other solutions, then only choice is to build work around and BYPASS ETL layer completely.
At some point, the workarounds will become complex as the initial solution itself which will end up with “Spaghetti Architecture”.
Properties
Extensibility: Should add own components to the system
Integrations: To be able to delegate external systems.
Automation Maturity: Many ETL tools offer no-code or UI driven experiences. This is great for prototyping, but when thinking about prod implementation consider how this tool fit into an organization for continuous production deployment.
If the tool does not have an API or an easy-to-use configuration, then the AUTOMATION will be very limited
Cloud Architecture fit
Most of ETL or open source tools were built on age of on-premises solutions and monolithic data warehouses. Most of them are some of form of integrate with cloud but not fully. Be cautious choosing the tool which is fit for cloud architecture.
Conclusion
For maximum flexibility, functional layer in the data platform should be separate but loosely coupled.
Apache Spark supports both Ingestion and Processing, In future, If needs to be changed some other tool for processing then it’s challenge to implement both Ingestion as well as processing. To avoid this, separate the functional layers.
Leave feedback about this